 We have a love-hate relationship with the p-value cutoff of <0.05. A p-value right below this cutoff (say, p=0.04) actually constitutes a surprisingly weak level of evidence (1). Thus, the idea of lowering the p-value cutoff has been around for a while. Unfortunately, this wouldn't really fix our problems with p-values.
We have a love-hate relationship with the p-value cutoff of <0.05. A p-value right below this cutoff (say, p=0.04) actually constitutes a surprisingly weak level of evidence (1). Thus, the idea of lowering the p-value cutoff has been around for a while. Unfortunately, this wouldn't really fix our problems with p-values.
Cutoff values for lab tests are silly
Let's start by exploring cutoff values in general. Imagine an outpatient for whom we are trying to rule-out pulmonary embolism. A D-dimer is ordered and comes back at 502 ng/ml, barely above the cutoff value of 500 ng/ml. This is a “positive” D-dimer, so the patient will receive a CT scan. We've all done this, based on accepted protocols. But really… does it make sense?
 Usual interpretation of D-dimer is shown above. A D-dimer of 502 ng/mL is regarded as “positive” whereas a D-dimer of 499 ng/mL is regarded as “negative.” The difference between these measurements is both clinically meaningless and below the analytic precision of the test. Nonetheless, if the D-dimer is 502 ng/mL we will order a CT scan, whereas if the D-dimer is 499 ng/mL we will skip the scan. Patient management depends on random variation in the D-dimer assay. That's illogical.
Usual interpretation of D-dimer is shown above. A D-dimer of 502 ng/mL is regarded as “positive” whereas a D-dimer of 499 ng/mL is regarded as “negative.” The difference between these measurements is both clinically meaningless and below the analytic precision of the test. Nonetheless, if the D-dimer is 502 ng/mL we will order a CT scan, whereas if the D-dimer is 499 ng/mL we will skip the scan. Patient management depends on random variation in the D-dimer assay. That's illogical.
A binary approach to interpreting D-dimer is silly in other ways as well. This approach equates a D-dimer of 502 ng/mL with a D-dimer of 3,000 ng/mL (both are “positive”). Of course, the higher value should be more worrisome. When all “positive” tests are lumped together, information is lost.
Test interpretation without cutoff values
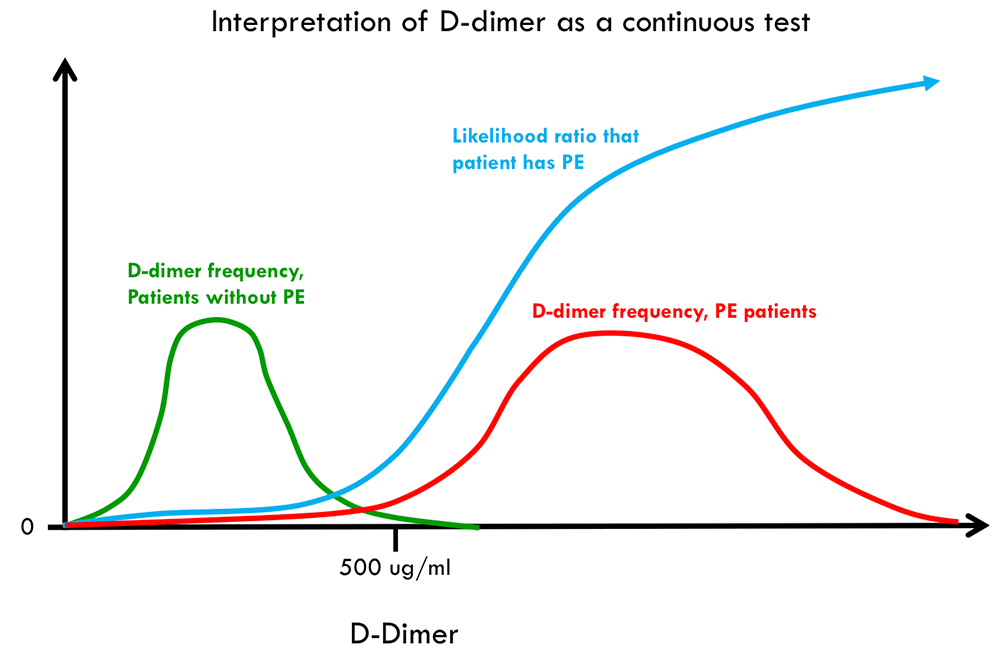 A more nuanced approach to interpreting the D-dimer is shown above. Based on the distribution of D-dimer values among patients with and without PE, a likelihood ratio function could be generated (blue curve above). This would calculate the likelihood ratio that the patient has a PE as a function of the D-dimer value. The test wouldn't result as “positive” or “negative,” but rather would result in the form of a likelihood ratio. For example, one might imagine the following results:
A more nuanced approach to interpreting the D-dimer is shown above. Based on the distribution of D-dimer values among patients with and without PE, a likelihood ratio function could be generated (blue curve above). This would calculate the likelihood ratio that the patient has a PE as a function of the D-dimer value. The test wouldn't result as “positive” or “negative,” but rather would result in the form of a likelihood ratio. For example, one might imagine the following results:
- D-dimer 499 ng/ml ==> likelihood ratio 0.1
- D-dimer 502 ng/mL ==> likelihood ratio of 0.11
- D-dimer 3,000 ng/mL ==> likelihood ratio of 9
In order to use this test, the clinician would first need to formulate a pre-test probability that the patient has a PE. Based on the D-dimer value and the resulting likelihood ratio, this could be used to calculate a post-test probability. Compared to the binary interpretation of D-dimer, this strategy has notable differences:
- It becomes obvious that the post-test probability is primarily dependent on the pre-test probability. This places a greater burden on the clinician to generate an accurate pre-test probability.
- The D-dimer test isn't viewed as a binary “truth machine” which will do all the work. Instead, the D-dimer is merely a modifier of our assessment of the risk of disease.
We should interpret lab tests in this more accurate fashion. Why don't we? Well, it's a lot more work. It's easier to fly through an oversimplified algorithm using D-dimer as a positive/negative test, rather than taking the time to generate a quantitative pre-test probability (2). It's also easier for the test manufacturer to create a single cutoff value, instead of a complex likelihood-ratio curve. In short, our use of D-dimer as a binary test is based on prioritizing simplicity over accuracy.
A cutoff for p-values is silly
 This is what we've all learned in statistics class. The clinical trial functions as a binary truth-machine. Insert any hypothesis, and the trial will yield a p-value and true/false answer. We like this approach because it is simple, objective, and widely accepted. It follows the rules. Journals like it. Unfortunately, it has major problems:
This is what we've all learned in statistics class. The clinical trial functions as a binary truth-machine. Insert any hypothesis, and the trial will yield a p-value and true/false answer. We like this approach because it is simple, objective, and widely accepted. It follows the rules. Journals like it. Unfortunately, it has major problems:
- A p-value slightly below 0.05 constitutes a weak level of evidence (roughly equivalent to a likelihood ratio of ~3). This level of evidence cannot prove the hypothesis to be true.
- The p-value is degraded into a binary test. Similar to the D-dimer above, when we lump together different p-values we lose information. There is an enormous difference between p=0.049 and p<0.001, but according to the above model these two values are equivalent.
- This strategy attempts to summarize an entire study with a single number, the p-value. This over-simplification ignores other important parameters (e.g. effect size, confidence intervals).
- This approach ignores the pre-study probability that the hypothesis is correct. For example, imagine testing the hypothesis that therapeutic massage cures cance. Using the above strategy, one out of twenty trials would conclude that massage cures cancer. When we focus narrowly on one study while ignoring prior evidence, we are easily fooled by an aberrant study
Resuscitating the p-value

Shift the cutoff value?
Recently Johnson suggested that we should decrease the cutoff for a “significant” p-value to <0.005. This would help stem the tide of false-positive studies which are based on marginal p-values. However, shifting the p-value cutoff fails to fix the most pervasive problems of traditional study interpretation listed above.

The reality is that no magical p-value cutoff exists which can separate truth from fiction. p-values occur along a continuum. The lower the p-value, the less likely the results were obtained by chance. Any cutoff which we choose represents a childish simplification of reality. Shifting the p-value cutoff from 0.05 to 0.005 replaces one arbitrary cutoff with another equally arbitrary cutoff.
Create p-value tiers?

One step away from binary p-value cutoffs might be to express p-values in terms of tiers of significance. This could retain the traditional 0.05 boundary between “non-significant” and “significant,” to prevent widespread confusion. However, it would remind us that p-values exist on a continuum. Furthermore, it would emphasize that marginal p-values (e.g., 0.01-0.05) only constitute a weak level of evidence.
Abandon cutoffs entirely?

Above is an alternative approach. It is complicated and subjective. It breaks conventional rules about p-value cutoffs. However, this approach resolves problems involved in standard study interpretation:
- There is no specific p-value cutoff, but instead the actual p-value is considered directly. It is recognized that marginal p-values constitute a weak level of evidence, whereas lower values constitute stronger evidence. Examining the p-value magnitude directly maximizes the amount of information that can be gained from it.
- Other statistical information isn't ignored (e.g. confidence intervals, effect size, fragility index).
- Evidence is considered in the context of prior studies. This avoids being misled if the current study is an outlier.

Unfortunately, the more thoughtful we are, the less objective we become. The standard approach to study interpretation follows nice clean rules: if p<0.05 accept, if p>0.05 reject. A more thoughtful approach lacks simple rules. For example, we might choose to reject a hypothesis even if p<0.05. Statisticians would likely find this sort of subjective interpretation to be heretical. Subjective interpretation generates disagreement, because different people will interpret data differently. Such disagreement is uncomfortable, but it reflects the reality that most studies aren't 100% definitive. Alternatively, consensus about the unknown based on arbitrary rules is dogmatism.

- Science is facing a crisis of reproducibility in part due to the standard approach to p-values. There are major problems with this approach:
- The pre-test probability that the hypothesis is valid is often ignored.
- Statistics other than p-value are usually ignored (e.g. effect size, fragility index).
- The strength of p<0.05 is overestimated (e.g., p-values of 0.01-0.05 actually constitute a weak level of evidence).
- Dividing p-values into several tiers could provide a cognitive scaffold to avoid dichotomous thinking about p-values as significant/insignificant. However, this approach still involves arbitrary cutoffs.
- A more integrative approach to interpreting studies could help resolve these issues (figure below). This would evaluate the hypothesis more globally, with the p-value being only one piece of evidence to be considered. No cutoff value would be used to evaluate the p-value, but rather the exact p-value would be considered in the context of the study and additional statistical data. Unfortunately, this approach is less objective.

Related
- Proposal to reduce p-value cutoff to <0.005
- Johnson 2018
- Commentary by Ioannidis in JAMA.
- Prior posts on p-value
Notes
- The low level of evidence provided by borderline p-values has been explored previously on the blog. If you're not aware of this issue then it might be best to start by reading prior posts here and here.
- Generating a quantitative pre-test probability is very hard, and we could use better tools to help us do this accurately. Recent studies suggest that physicians often over-estimate the baseline probability of pulmonary embolism in outpatients (e.g. a recent study was done where the entire population had a risk of PE ~2%, which is very close to the test threshold for PE, suggesting that many of these patients probably didn't require an evaluation at all; Buchanan 2017).
- Standard null-hypothesis testing involves comparing the data to the null hypothesis only. Alternatively, Bayesian statistics involves comparing the data to both the null hypothesis and an experimental hypothesis. The Bayes Factor is essentially a likelihood ratio that the experimental hypothesis is valid. This value will depend on exactly how the experimental hypothesis is defined.

- Pulmcrit wee: The cutoff razor - April 15, 2024
- PulmCrit Blogitorial – Use of ECGs for management of (sub)massive PE - March 24, 2024
- PulmCrit Wee: Propofol induced eyelid opening apraxia – the struggle is real - March 20, 2024
There’s a lot that’s excellent in this blog, including — simply lowering the threshold for “significant” doesn’t even begin to address the many big problems with p-values, and 2) a Bayesian approach to data, rather than binary y/n analysis, is far better (not just for lab tests, or for P-values). What’s missing, though — and is left out of John I’s paper as well — is the sad truth that P-values “ask a humanly meaningless question” … to wit, “would we be likely to see these results if the 2 things being compared are really EXACTLY THE SAME?” Meaningless, b/c… Read more »
Thank you, absolutely agree. The answer to any clinical question requires thoughtful synthesis of *numerous* statistics (not only p-value, but also effect size, confidence interval, fragility index, number needed to treat vs number needed to harm). This also needs to be combined with prior studies and common sense. For decades we have been myopically focused on the p-value, while often ignoring the larger clinical picture. The solution to this problem isn’t necessarily better statistics, but rather that we need to be better doctors (exercising our judgement, rather than blindly adhering to statistical orthodoxy).
Great post Josh
I think we need to teach Bayes factor to allow interpretation of statistics
To do this we need to make it easily understood by the generations who are addicted to Ps
I think the tiered approach using a scale of~5 levels of “power” mapped onto the relationship between p-values and Bayes (likelihood ratios) would be easily digestible
Of course, it would be nice if articles include this information to assist in stats reading
A few are starting to do so. Editors, let’s do it?
Casey
Thanks Casey. Reforming statistics will not be easy. Underlying rot in our statistical systems is an ugly problem, so there is a natural tendency to ignore or deny it. Articles about this date back for decades, but little has been done about it. I’m hopeful that FOAMed can help us discuss these issues and become more mindful of them.