 Getting started: The HYPRESS trial
Getting started: The HYPRESS trial

The new HYPRESS trial tests whether steroid could prevent deterioration from sepsis into septic shock. The study found no significant benefit from steroid, but I thought it was underpowered. However, an accompanying editorial in JAMA didn’t even mention power.
This raises some questions: How can we measure type-2 error? How should it be reported? What is an acceptable level of type-2 error?
Background: Type-2 error is the forgotten error type.
 Most discussions of statistics focus on type-1 error, the risk of incorrectly concluding that a therapy works. P-values are widely presented and debated (this blog has discussed type-1 error here and here). Meanwhile, type-2 error is usually relegated to a power calculation buried in the fine print of the methods section. There is conventionally a double-standard that type-1 error must be below 5%, but type-2 error may be up to 20%.
Most discussions of statistics focus on type-1 error, the risk of incorrectly concluding that a therapy works. P-values are widely presented and debated (this blog has discussed type-1 error here and here). Meanwhile, type-2 error is usually relegated to a power calculation buried in the fine print of the methods section. There is conventionally a double-standard that type-1 error must be below 5%, but type-2 error may be up to 20%.
As mortality rates in critical care decrease, it is increasingly difficult to prove the efficacy of new treatments. This may lead to an increase in “negative” trials over time. Unfortunately, negative RCTs are often underpowered to prove equivalence (Penington 2008). Thus, many “negative” trials may actually be inconclusive trials:
 How can we measure type-2 error?
How can we measure type-2 error?


A power calculation is performed before starting a RCT, to determine how many patients must be included to avoid type-2 error. Unfortunately, this calculation depends on many assumptions (e.g. mortality rate and effect size). Such assumptions are frequently incorrect, for example due to over-estimation of the expected effect size (“delta-inflation” that causes the study to be underpowered; Aberegg 2010). Overall, power calculations don’t guarantee adequate power.
Repeating a power calculation after the study is over shouldn’t be done (Hoenig 2001). This creates problems regarding circular logic.
The best way to determine the power of a completed study seems to be examination of how wide the confidence intervals are (Pennington 2008). However, there doesn’t appear to be any standardized way that this is calculated or reported. How should this be done?
A strategy for analyzing power
Absolute power vs. relative power
Power may be divided into two types: absolute power and relative power. The table below illustrates this concept in terms of mortality, but it could be applied to any outcome:
 An example may help. Let’s imagine that we performed a massive RCT of subcutaneous heparin for DVT prophylaxis among low-risk patients on the psychiatry ward. The primary outcome is death from pulmonary embolism. Results show that heparin causes a non-significant reduction in mortality (0/9000 with heparin vs. 2/9000 without heparin, p~.99).
An example may help. Let’s imagine that we performed a massive RCT of subcutaneous heparin for DVT prophylaxis among low-risk patients on the psychiatry ward. The primary outcome is death from pulmonary embolism. Results show that heparin causes a non-significant reduction in mortality (0/9000 with heparin vs. 2/9000 without heparin, p~.99).
- The absolute power of this study is high. It is very clear that heparin isn’t causing much absolute mortality benefit (<<1%, to be sure).
- The relative power of this study is low. It’s possible that heparin causes a 100% relative reduction in mortality, but the study is underpowered to prove this.
The absolute and relative power have different implications for generalizability:
- The absolute power describes how effective this intervention is within a specific clinical context. For example, this study convincingly proves that heparin is ineffective among low-risk psychiatric patients.
- The relative power of the study has implications for generalizability: how well would heparin work in a high-risk population with a greater PE rate?
Power could be interpreted as follows (1):
 Calculating absolute & relative power
Calculating absolute & relative power
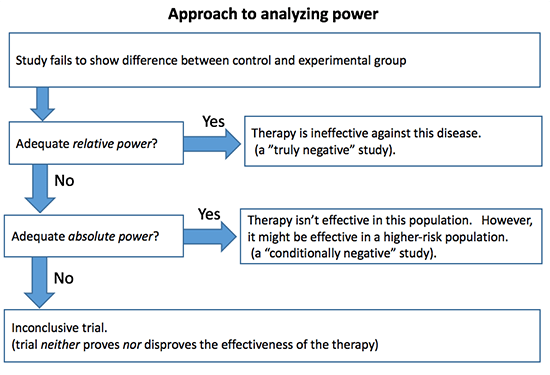
Absolute and relative power can often be inferred from confidence intervals reported in the study. However, if the study doesn’t include these values, they may be calculated as follows:
Absolute Risk Reduction = (% bad outcome with therapy) – (% bad outcome in control group)
Absolute power may be calculated as the 95% confidence interval of the absolute risk reduction (2). This can be done using this online calculator.
Relative Risk = (% bad outcome with therapy)/(% bad outcome in control group)
Relative power may be calculated as the 95% confidence interval of the relative risk. This can also be done using an online calculator (3).
Analysis of 20 major critical care studies
To test-drive these concepts, let’s examine 20 recent negative studies pertinent to critical care in NEJM and JAMA (4). Relative and absolute power of these studies are calculated as described above (studies 1-10 are from NEJM, 11-20 from JAMA):

 These studies vary substantially. However, they can be roughly divided into three groups:
These studies vary substantially. However, they can be roughly divided into three groups:
- Good absolute and relative power (e.g., studies 1 and 8). These are large and well powered studies, all with >2000 subjects enrolled. The number of events was large as well (>800 per trial).
- Good absolute power but poor relative power (e.g., studies 5, 6, 18). These are large studies, but they were studying infrequent events (e.g. coronary stent thrombosis, stroke while bridging anticoagulation). It is clear that therapy doesn’t have a significant absolute effect, but it remains unknown whether there is a relative difference.
- Insufficient absolute or relative power (e.g. studies 11 and 15). These are relatively smaller trials (e.g. ~350 patients enrolled) which are inconclusive.
This can be represented schematically:
 How much power is “enough” power?
How much power is “enough” power?
 Power depends on effect size. For example, it’s impossible to perform a study which will exclude a tiny effect size (e.g. a 0.001% change). Alternatively, it’s not difficult to exclude an unrealistically large effect size (e.g. 50% mortality benefit).
Power depends on effect size. For example, it’s impossible to perform a study which will exclude a tiny effect size (e.g. a 0.001% change). Alternatively, it’s not difficult to exclude an unrealistically large effect size (e.g. 50% mortality benefit).
The question is whether the study makes it unlikely that the therapy has a clinically relevant effect size. What constitutes a clinically relevant effect size is a matter of judgement that depends on potential risks, benefits, and costs. For example, consider two studies with similar numbers, but opposite interpretations:
- Study #2 above tested the effect of prednisolone on all-cause mortality among patients with alcoholic hepatitis (Thursz 2015). The study could have failed to detect an absolute mortality benefit of 8%. Such a difference would be clinically important, making this study underpowered. Further investigation may be warranted.
- Study #16 above tested the ability of immune-modulating nutrition to reduce infections (van Zanten 2014). This study may have failed to detect a 10% reduction in infection rate. However, infection is a less important endpoint than mortality. Furthermore, this study detected signals of potential harm (increased mortality). Therefore, this therapy doesn’t warrant further investigation in this patient population.
The approach to reporting power is variable
 This table shows how these studies reported the power of the primary endpoint within the abstract (5). These are all negative studies with similar design, published in the same two journals. Nonetheless, there is little consistency about how power is reported. Lack of consistent reporting makes it hard for us to achieve a well-calibrated appreciation of power. It also allows authors to selectively report the most favorable statistic.
This table shows how these studies reported the power of the primary endpoint within the abstract (5). These are all negative studies with similar design, published in the same two journals. Nonetheless, there is little consistency about how power is reported. Lack of consistent reporting makes it hard for us to achieve a well-calibrated appreciation of power. It also allows authors to selectively report the most favorable statistic.
Finally… getting back to the HYPRESS trial.

 The power of the HYPRESS trial is shown above (study #11):
The power of the HYPRESS trial is shown above (study #11):
- 95% confidence interval of the absolute risk reduction is -10.6% to +7%
- 95% confidence interval of the relative risk reduction is 0.62-1.38
These confidence intervals don’t exclude the possibility that steroid could cause a 10% absolute and 38% relative reduction in shock. Such differences would be clinically meaningful, indicating that this study is underpowered to exclude absolute or relative efficacy. This isn’t a positive study or a negative study: it is an inconclusive study.

- Whenever a study doesn’t detect an effect from therapy, a primary consideration is whether the study was sufficiently powered to exclude a clinically meaningful effect.
- Power can be divided into absolute vs. relative power (table below). These are measured differently and address different questions.
- Negative trials in NEJM and JAMA vary enormously in their power and how it is reported.
- Some “negative” trials reported in major journals are actually inconclusive due to inadequate power.
 Notes
Notes
- Certainly, study interpretation depends on a lot more than just power (e.g. prior studies, risks, benefits, costs, confounding factors, etc.). For example, I’ve deviated from this algorithm in my interpretation of the VANISH trial here.
- There is no agreement about whether to use an 80%, 90% or 95% confidence interval here. I use a 95% confidence interval because this is the most common confidence interval which is used in statistics (which allows us to have some general experience with how to interpret it). Also, 95% confidence intervals are frequently reported in the original publications, so this allows values calculated here to be compared with reported values in the literature.
- An alternative approach to expressing relative power is the odds ratio. Either approach is completely valid. I prefer the relative risk because this is a more intuitive number (we typically think about frequencies rather than odds). For further discussion of odds ratios vs. relative risk please see Viera 2008.
- Studies were selected on the following basis: (a) they had to be negative studies, (b) they had to be relevant to critical care medicine and of general interest, and (c) they had to involve a binary primary endpoint (e.g. mortality). Studies were excluded if their primary endpoint was time-to-event analysis, length-of-stay, etc. If there were multiple co-primary endpoints and one of these was a binary event, the study was included here.
- Papers that didn't directly report power in the abstract instead reported confidence intervals for control and experimental groups (but not the confidence interval of the difference). This may give readers an indirect sense of the absolute power.
Related
- Pocock 2016: The primary outcome fails- What next? Analyzing a study whose primary outcome hasn’t detected a difference is complicated. This post has focused on power, but there’s certainly a lot more to it. Pocock’s review in the NEJM discusses the broader range of issues at play.
- Type-I error:

- Pulmcrit wee: The cutoff razor - April 15, 2024
- PulmCrit Blogitorial – Use of ECGs for management of (sub)massive PE - March 24, 2024
- PulmCrit Wee: Propofol induced eyelid opening apraxia – the struggle is real - March 20, 2024
Thank you for a customarily excellent post, easily digestible too 😀
Glad you enjoyed it. Statistics usually isn’t super exciting, but it’s important.
I’d just like to add that underpower studies with positive results needs to be read with precaution.
Because there is a high chance that the difference observed is bigger than the real difference, allowing to make inacurrate assumption in the effectivness of treatment.
Source : Colquhoun, D. (2014). An investigation of the false discovery rate and the misinterpretation of p-values. Open Science, 1(3), 140216.
Agree. An underpowered study with positive results represents type I error. A good way to sift this out is the fragility index, discussed here (https://emcrit.org/pulmcrit/fragility-index-ninds/). The maximal bases factor may be helpful as well (https://emcrit.org/pulmcrit/2×2-table-maximal-bayes-factor/). A general discussion of p-values is here: https://emcrit.org/pulmcrit/demystifying-the-p-value/